
Reading for Programmers
Posted by Piotr Limanowski on .TD;DR: Use a three-pass (verify-grasp-analyse) reading algorithm and get comfortable with reading hundreds of papers. Use org-mode (w/ helm-bibtex, org-ref and interleave) and keep the notes in check.
Introduction
With computing resources getting cheaper by a minute, the rise of functional and distributed programming, software business and academia are getting closer than ever. Modern software is able to and does rely heavily on advancements of the academics. Cutting edge research getting into everyday's code is not an uncommon act. We can either choose to ignore the backing concepts of the code we deliver or embrace the change and work our way into it. Either grab libraries, use the open source contributed solutions and ignore the inner workings or try to understand the ideas. Look under the kitchen sink whenever something falls down into the black hole. Following the scientific advancements requires a significant willpower and either way it merely leads toward 10 Stages of Reading a Scientific Paper1. You can however easily get beyond that by teaching yourself a method to skip the painful parts…
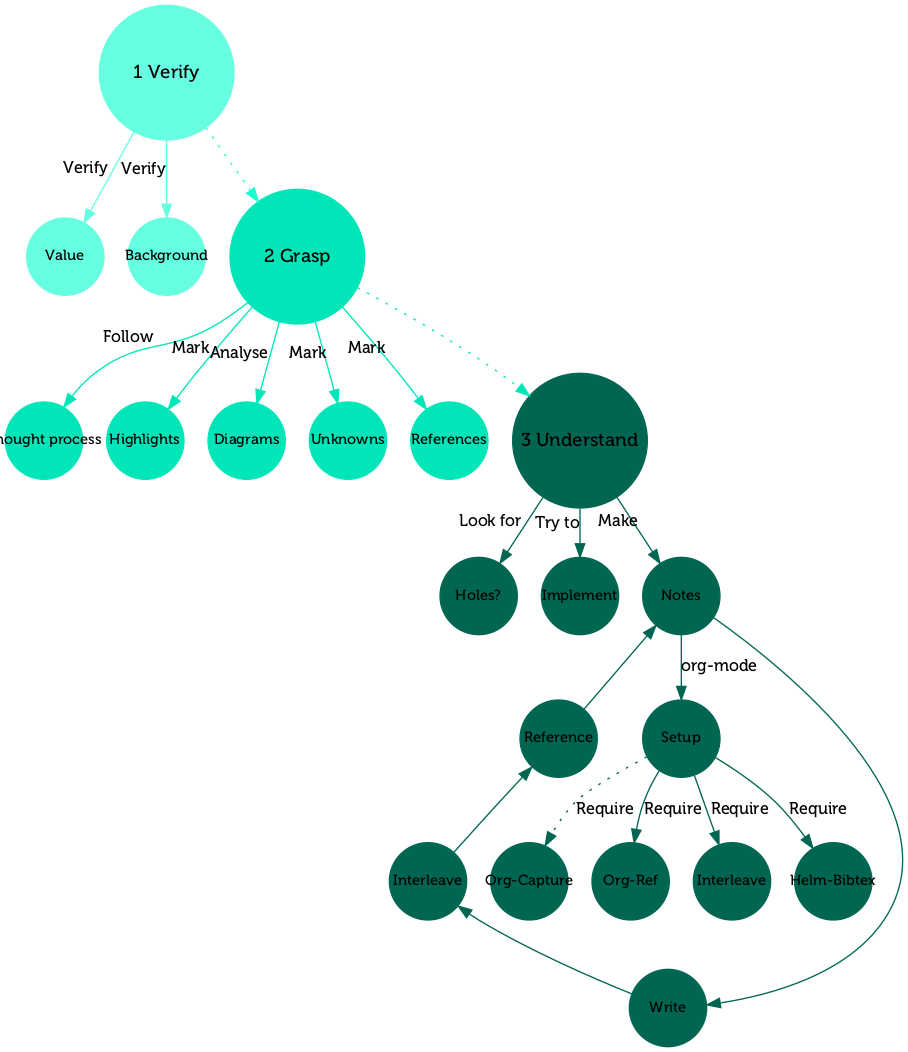
Three-pass reading
It's been said many times2, 3 that reading a paper (honestly reading anything that requires understanding sufficently advanced concepts) should be tackled in a multi-pass manner. The main concept here is that each time you pass the paper you do that with very specific aim in mind. At first you verify the paper and its contents, secondly you grasp the general ideas and thirdly you get to know the concepts throughly and get your notes flowing.
READY First pass - Verify
The first pass provides you with a high-level view of the contents. Helps you avoid getting stuck in a badly written, uninteresting, wrong or simply beyond your current knowledge text. To get the most from the first pass I usually start with references. And although statistically 80% of the authors never read the cited texts in full 4, they provide a great overview of what to expect. Whenever approaching a complex, long paper I tend to mark the cited papers I've read. So I can get back to my infamous notes) or verify the background. Reading the papers starts with the title, abstract and introduction which I read carefully the first time I approach a paper. They are the first sign of whether the article is the one to go with. After that I scan through the article focusing on section headings, graphical elements and math formulas. I also read the results and discussion section to have an overview of where I will be lead with the article. The author of "How to read papers"2 paper, that was recently trending over at HackerNews suggests that the first pass shall give you an answer to 5Cs:
- Category - what type of paper is this?
- Context - which other papers it is related to? which theoretical bases were used to analyze the problem?
- Correctness - do the assumptions appear to be valid?
- Contributions - what are the paper's main contributions?
- Clarity - is it well written?
For me after the first reading, aside from the bird's eye view of the paper, allows to decide whether I should give it a second pass. Personally I ask myself:
- What's in it for me?
- Do I have enough background?
Reading papers can greatly improve your knowledge, provide you with practical solutions, methodologies of doing things or even experimental design concepts.
Yet papers do require prior knowledge - a background. Whenever after the first pass I see a gaping hole of missing background I mark article as TODO, tag with :advanced: and leave it until I am able to read it or go through references and the Internet and build up the background.
READY Second pass - Grasp concepts
I start the second pass with the goal of grasping the concepts and supporting evidence so I can describe it to a fellow programmer over a beer.
I usually sync it to my Onyx Boox large screen epaper reader to avoid printing.
This allows me to conveniently follow thought process, paying attention to concepts without going deep into its execution.
While reading I mark, highlight or scribble notes on the side of the paper. A quick rescan will later show me the paper's major points.
I try to work my way through diagrams and graphical representations.
Whenever hitting stuff I do not comprehend, it's usually pretty easy to see whether it will prevent me from following the concepts this rendering further reading useless or it's a thing I can jot down and learn later on.
The blockers have to be handled immedietely before going any further. So… google that, search my notes, learn.
Next thing I also focus on on the second pass is inline references. Some of the references are instant hook, so I add them to TODO papers list.
With the second pass I have a scribbled, marked and highlighted article, understand the concepts and can share the idea.
The thing is however that for the essential concepts it's still not enough. Thus the third pass.
READY Third pass - Critique
The third pass is obviously for the highly interesting papers I need to comprehend. I work my way through the parts I missed previously and try to see the results/discussion in a larger spectrum. Ie. How does profunctor optics relate to extensive domains we've built? The third pass is also where I tend to differ from some of the academics. It is said, that in order to review a paper you need to recreate it without copying. I usually do that only with the papers that are vital to my work. I pick the tools I use and try to rebuild that. Indeed it can make one angry. It will get on your nerves and you will hate the ideas. But in the end the grand idea is usually worth it. The third pass usually ends up with a bit of code and notes. Or just the notes. But the notes are where it all belongs. Third pass is for the active reader. Even if the article is not core to the things I do and I decide not to fiddle around in REPL I am an active reader. I mark even more things, note stuff (that usually won't fit in margins) on the side. I don't copy stuff. Use my own words so I process it. I use structured notes - outline. I critically look for inconsistencies. Is the reasoning right? Is the samples number sufficient?
The Notes
I have been tinkering with the notes workflow for a couple of years. With lots of notes and papers read it gets tedious to grep files for related notes. And it is somewhere on the verge of madness to have it all stored in a paper notebook. As an avid Emacs uses I have been taking notes with the almighty org-mode. An extensible Emacs major mode for all things text/data related. With org-mode's minimal syntax and tree layout it is incredibly easy to structure and extend the simple, single-file knowledge base.
The workflow
I have been keeping a huge notes papers.org and a references papers.bib files for a couple of years now.
The files contain an abysmal list of books, papers and articles I've been tagging as TODO.
Usually to avoid fiddling around I just add a quick TODO of a document with an org-capture5 template (be it paper, article, link, whatever).
Every now and then (usually whenever picking the next paper to read) I go through the file and turn the captures into proper Bibtex references.
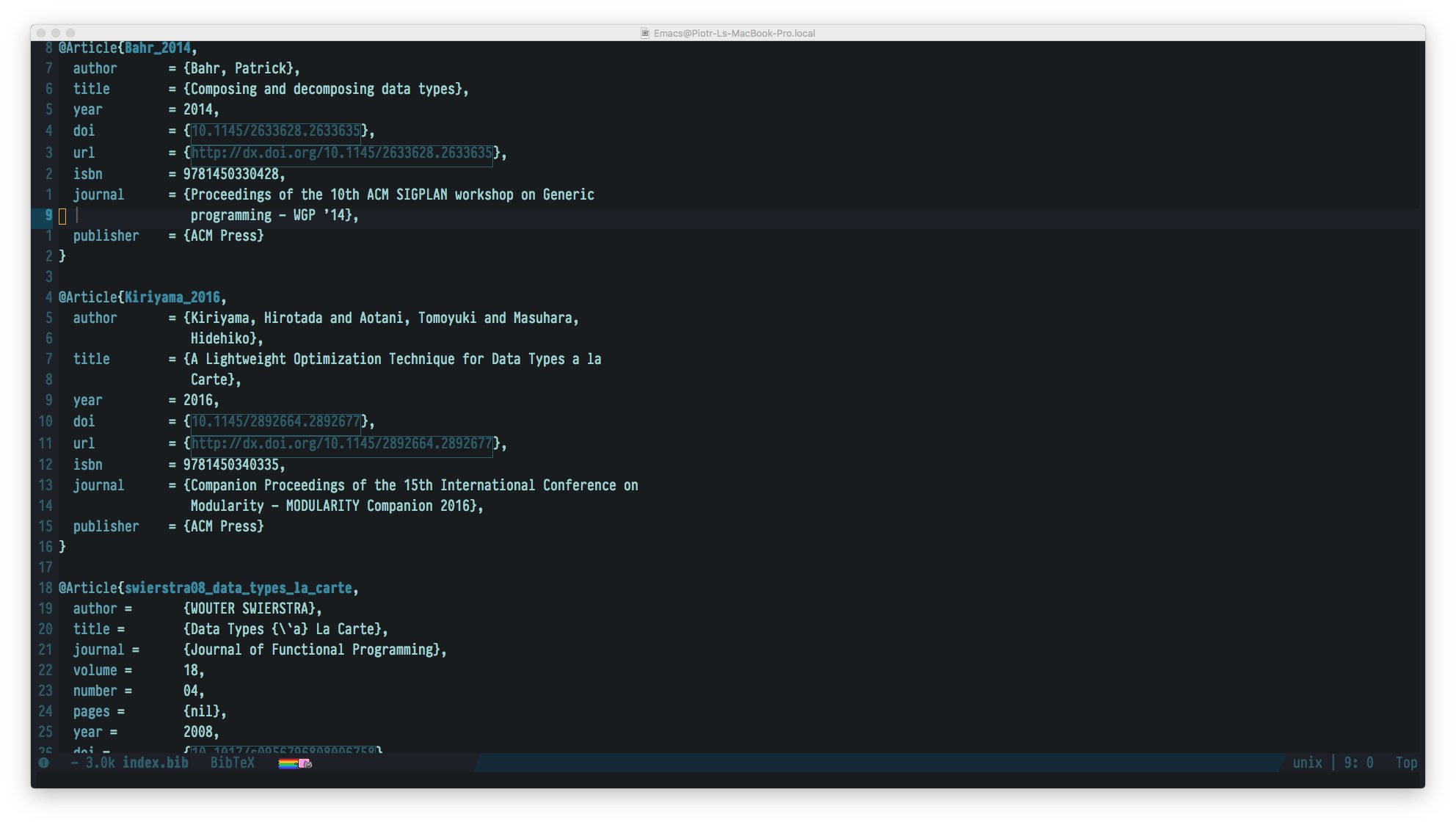
Figure 2: Bibtex has been a de-facto standard reference management system for years now
Bibtex has been a de-facto standard reference management system for years now. Hence it is perfectly possible to grab all the necessary document details from the Internet. Either by searching by name, title, tag or… a pdf file. I usually either drag and drop a downloaded pdf onto Emacs window with references files so it fetches the data on it's own. Or… just use the beautiful helm-bibtex which allows me to quickly access all the major scientific search engines from arxiv to google scholar.
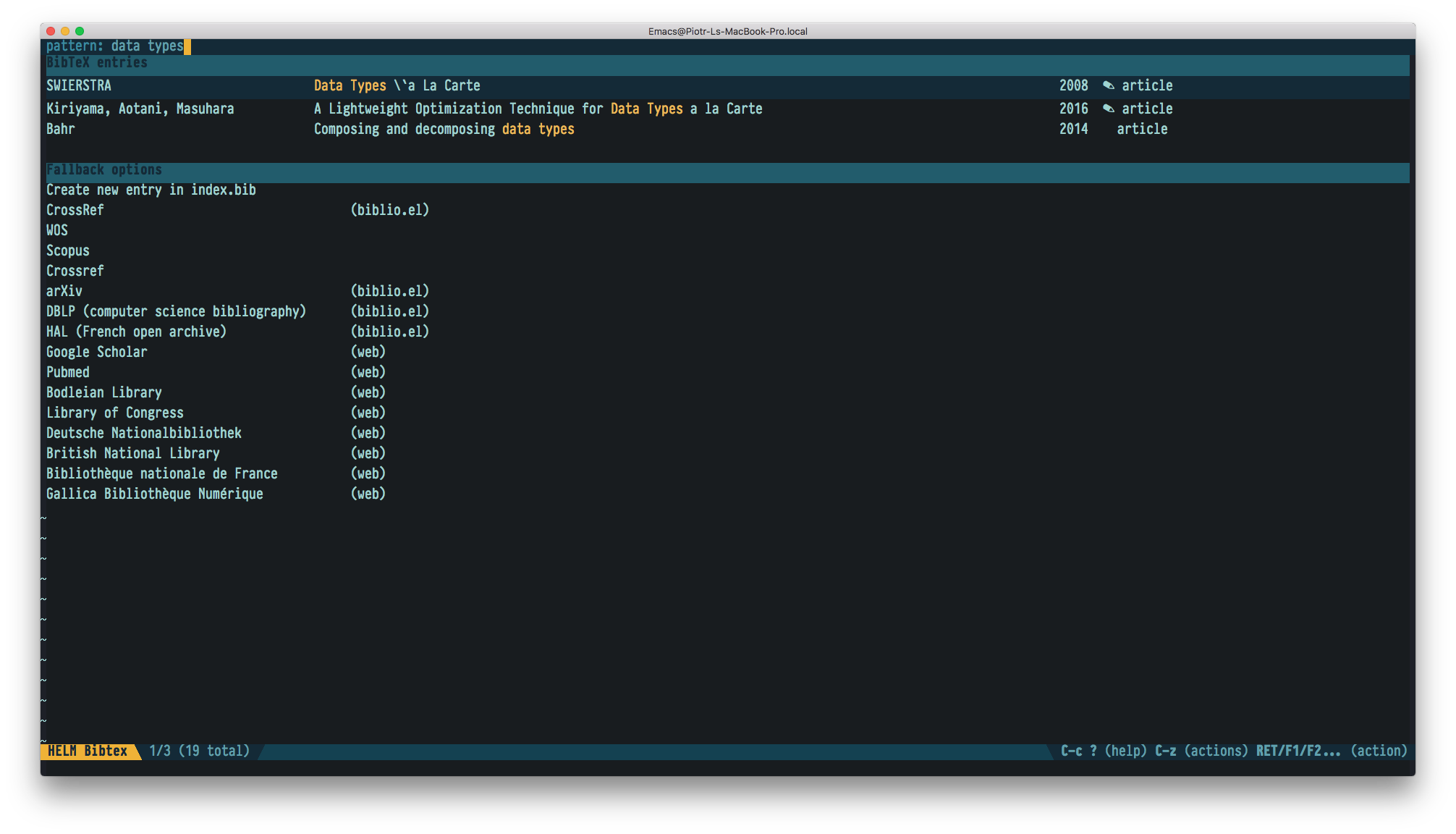
Figure 3: helm-bibtex allows quick access to references
I also turn the capture TODO into a document TODO task in the papers.org itself.
However to keep thing optimised, it gets done using the reference - enter org-ref. A quick shortcut and the reference and TODO are now linked.
My usual workflow for taking notes starts with the third pass which I usually do in Emacs' pdf-tools anyway.
Running a REPL or a worksheet side-by-side with a paper is invaluable. Same goes for taking notes.
And guess what, everything I have done so far enables me to use a single command to link notes to specific places in a pdf.
Enabling interleave mode (M-x interleave, duh) on given subtree (with :INTERLEAVE_PDF: property set) allows that by simply attaching pdf location. And voila:
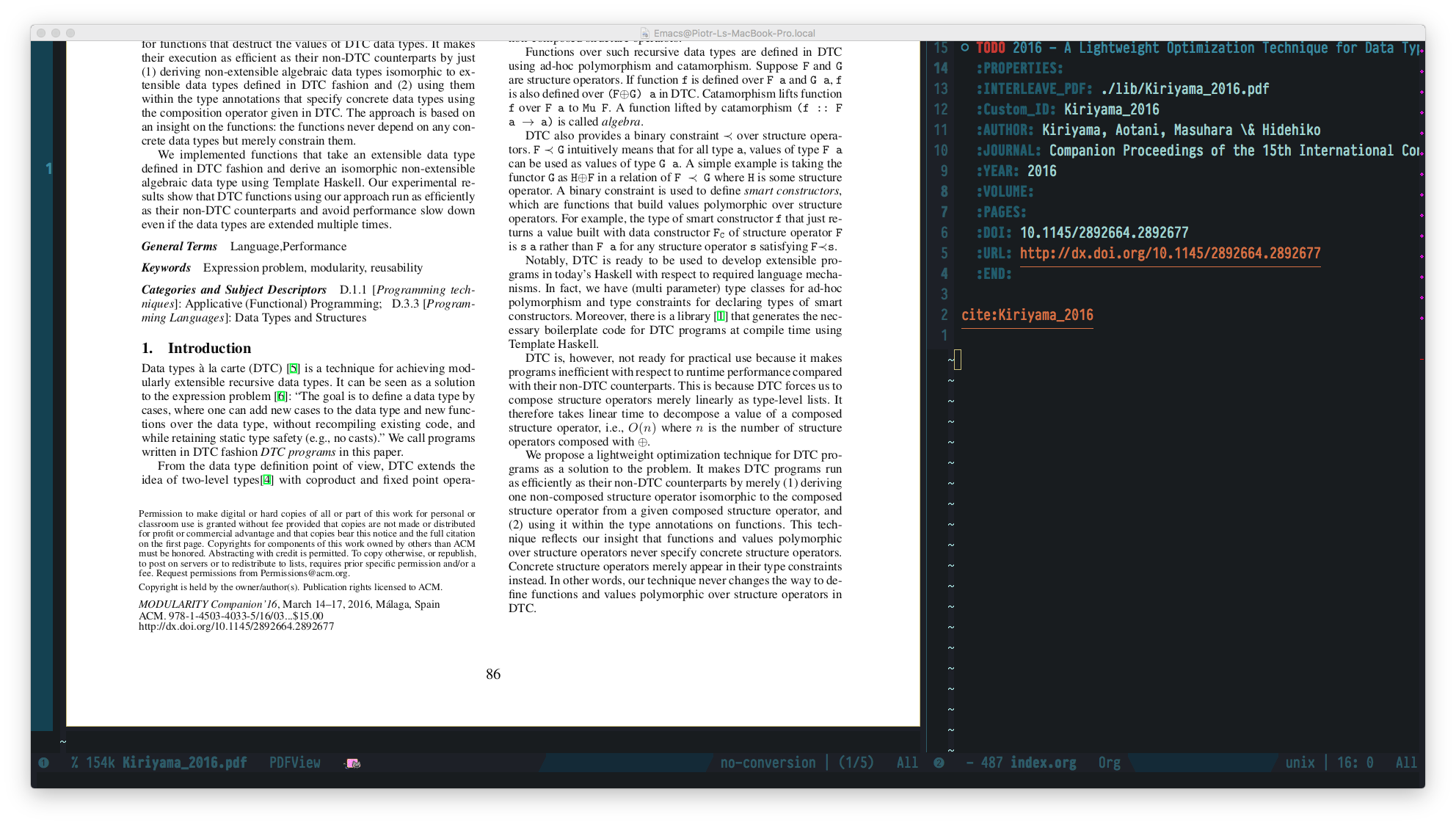
Figure 4: iterleave allows linking notes to pdf parts
With that at hand I'm able to effectively keep the notes neatly connected to source material. And between each other using org-mode subtree search and tags.
The setup
The setup is indeed prety straight-forward to achieve. A couple of packages and a minimal configuration options. I store my dotfiles in a github repository. My (now migrated from plain ol' init.el) spacemacs config's there as well. Feel free to roam around and steal stuff - dotfiles.codearsonist.com.
pdf-tools
A prereq for Emacs to be able to display pdfs properly. I'm using stock configuration without extra options.
org-ref
org-ref also requires just a minimal setup to get the wheels turning and the configuration corresponds the helm-bibtex one:
(setq org-ref-notes-directory "$SOME"
org-ref-bibliography-notes "$SOME/index.org"
org-ref-default-bibliography '("$SOME/index.bib")
org-ref-pdf-directory "$SOME/lib/")helm-bibtex
I guess org-ref config should be propagated down to the helm-bibtex one. But here's how you'd configure helm-bibtex directly:
(setq helm-bibtex-bibliography "$SOME/index.bib" ;; where your references are stored
helm-bibtex-library-path "$SOME/lib/" ;; where your pdfs etc are stored
helm-bibtex-notes-path "$SOME/index.org" ;; where your notes are stored
bibtex-completion-bibliography "$SOME/index.bib" ;; writing completion
bibtex-completion-notes-path "$SOME/index.org"
)interleave
None. Set the :INTERLEAVE_PDF: property on subtree in papers.org and you're done 🎉️
Picking the next paper
As a side note. The Internet is full of papers. Hackernews, Twitter stream, Reddit produce must read items quicker than we will ever be able to follow. From my personal experience though the best source of papers are simply references from other papers. Each specialty has its own paper 'canon'. Start with them and gradually work your way towards others either by following citations (CiteSeer, Google Scholar) or references directly. Keep in mind that citations number is a pretty good sanity check whenever a paper is getting recommended.
Summary
Armed with a method of reading scientific material I have read numerous deeply technical papers. Often beyond my usual knowledge level. The approach allows me for improving my reading skills (also see: 6) with each paper I read. The more I read the better my understanding is. I am able to share the knowledge by discussing it with other people. All the above is the basic workflow idea I have been working with and find it perfect for my needs. There is more to it including automated tag dependency graphing I have implemented. But that is a separate (long) story…
Footnotes:
Ruben, A. (2016). How to read a scientific paper. Accessed at 07/06/17
Pain, E. (2016). How to (seriously) read a scientific paper. Accessed at 07/06/17
Keshav, S. (2013). How to Read a Paper. Accessed at 07/06/17
Simkin, M.V. and Roychowdhury V.P. (2002). Read before you cite! Accessed at 07/06/17
Bayard, P. (2009). How to Talk About Books You Haven't Read. Bloomsbury USA